decide with confidence

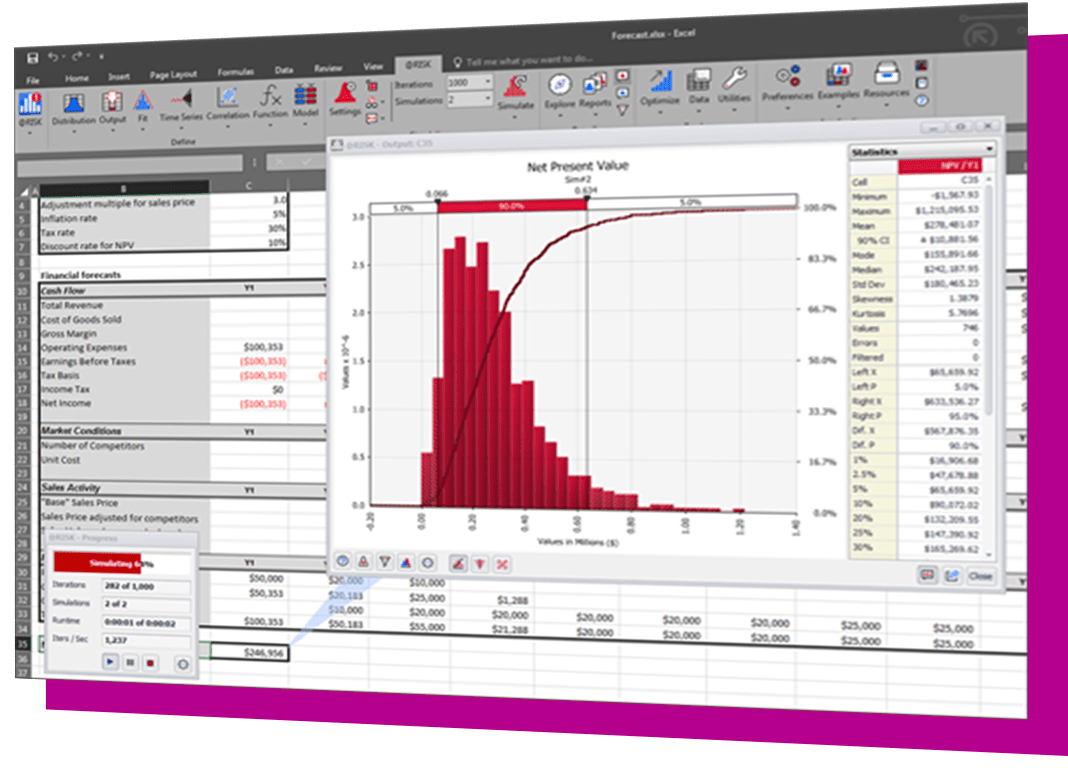
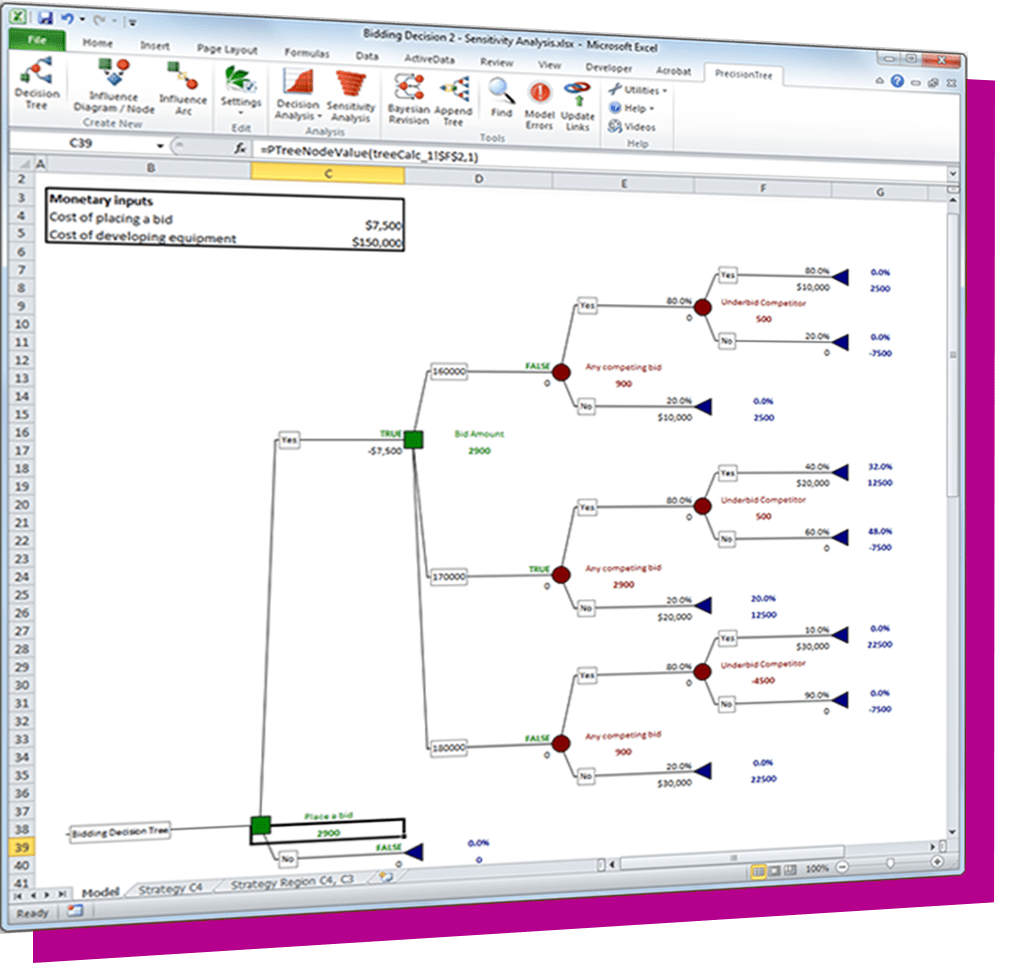
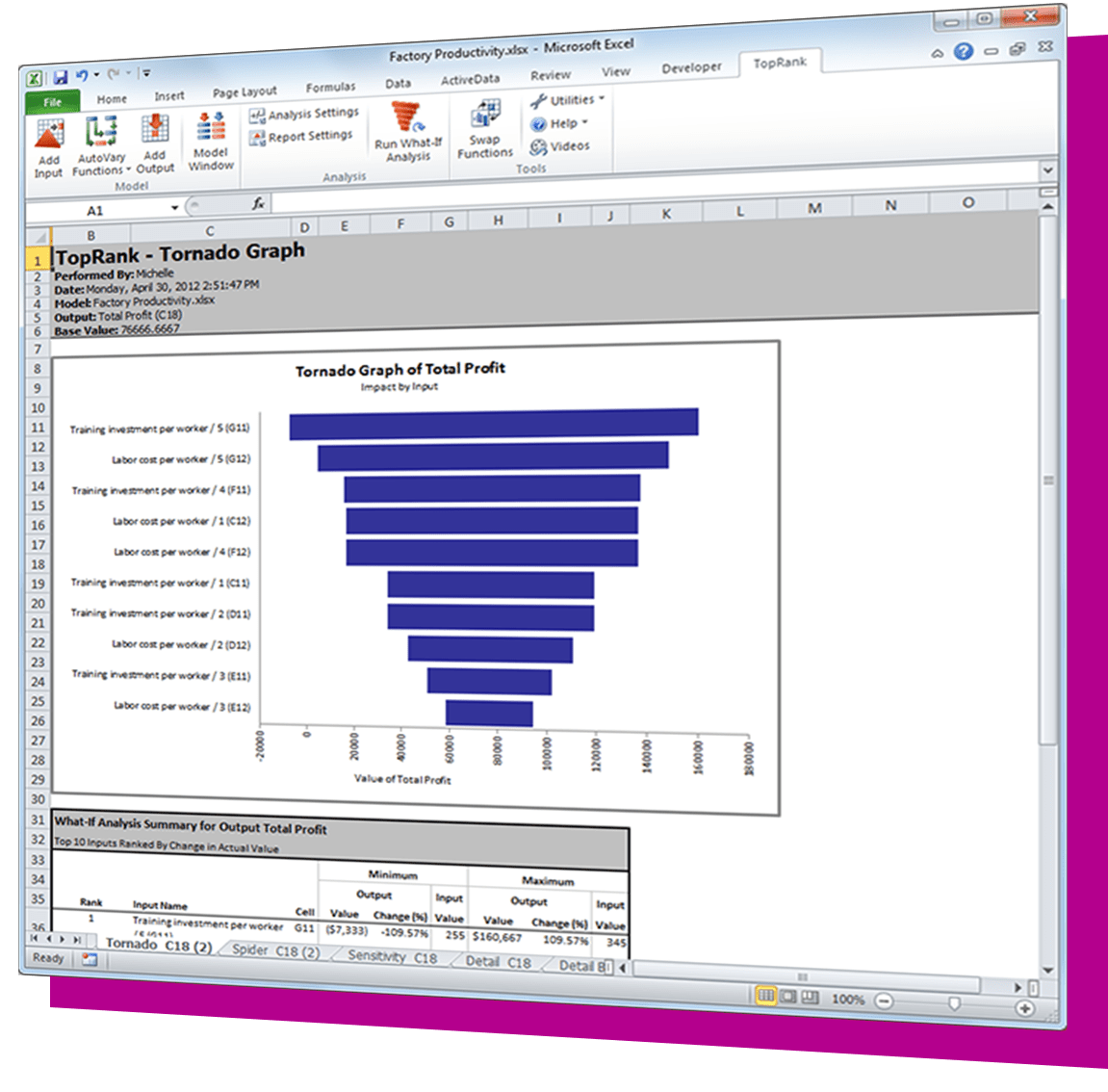
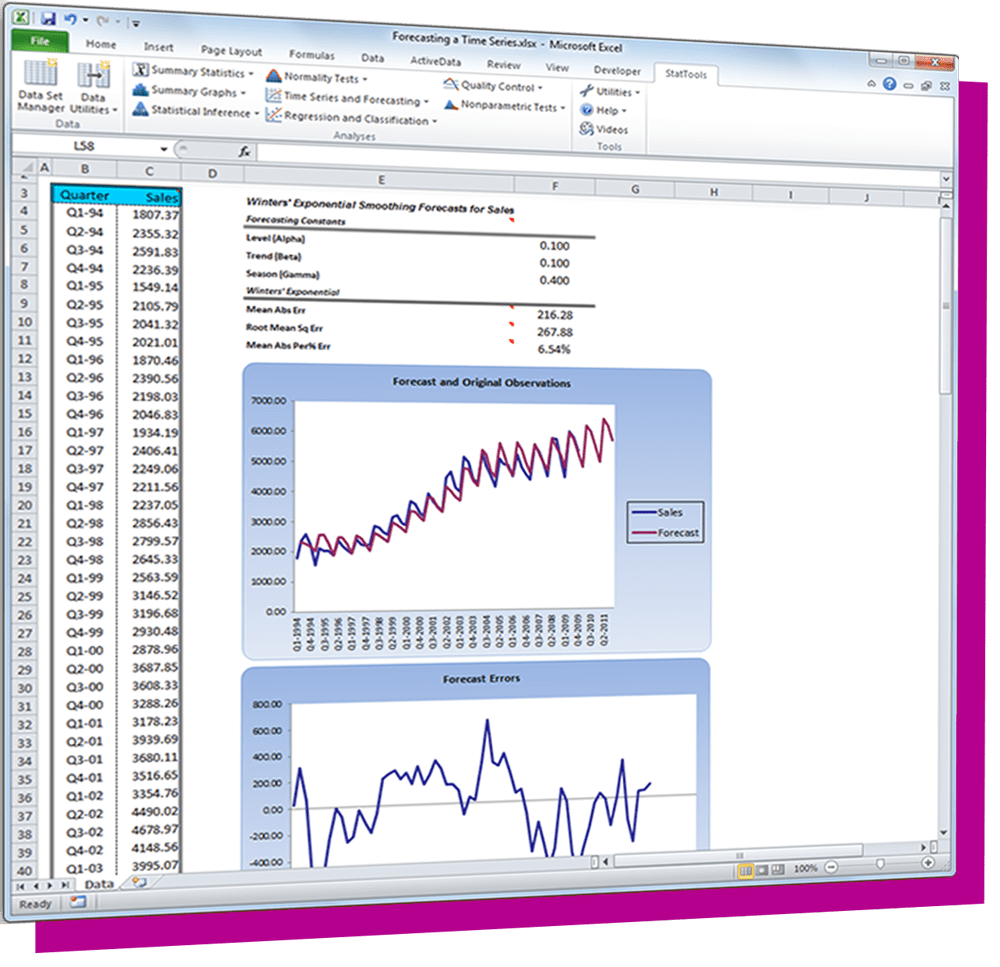
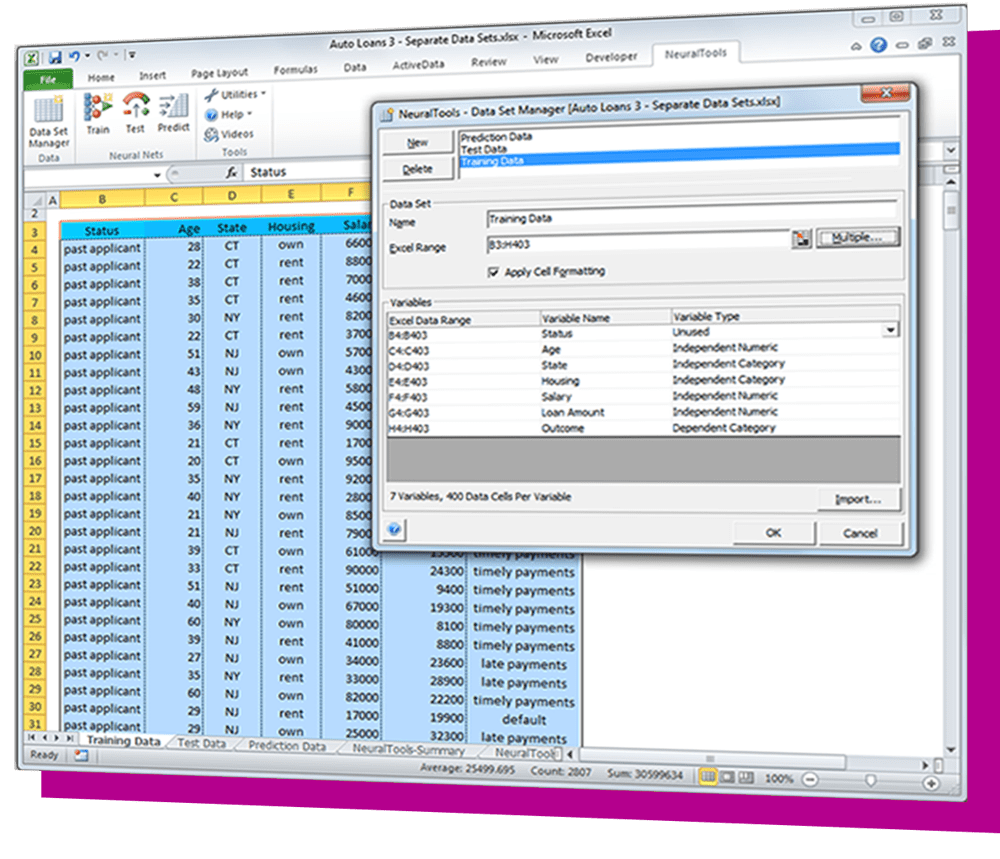
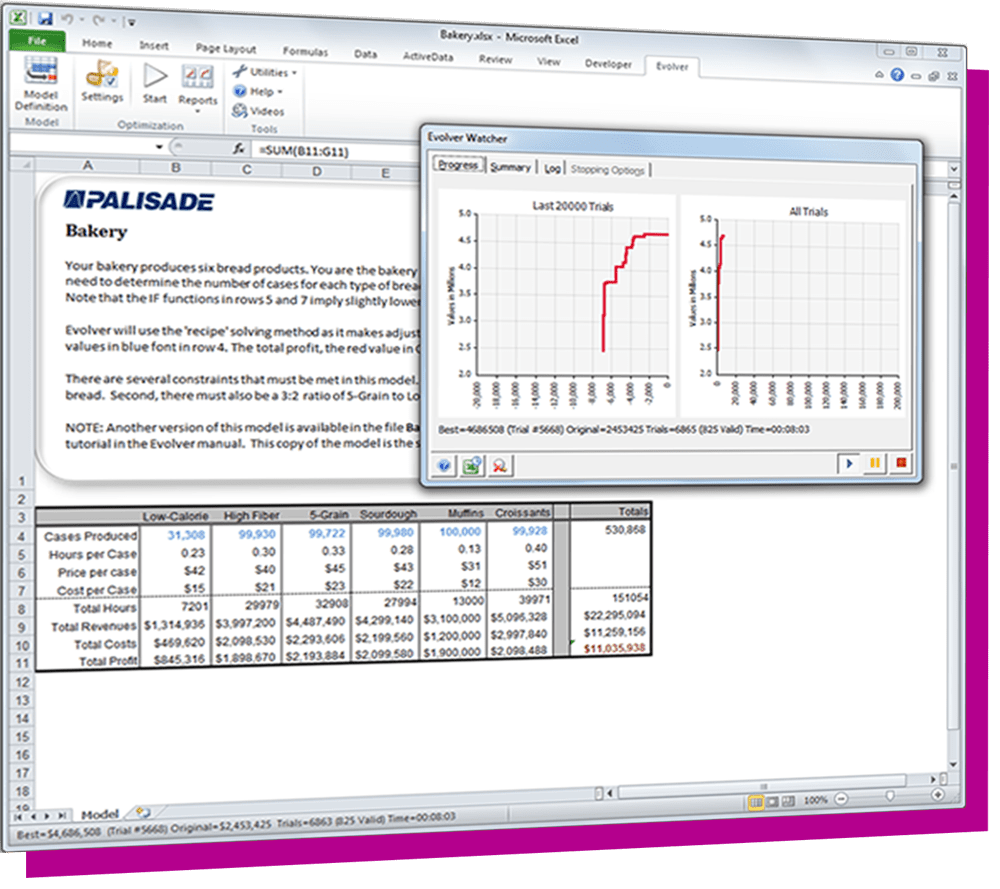
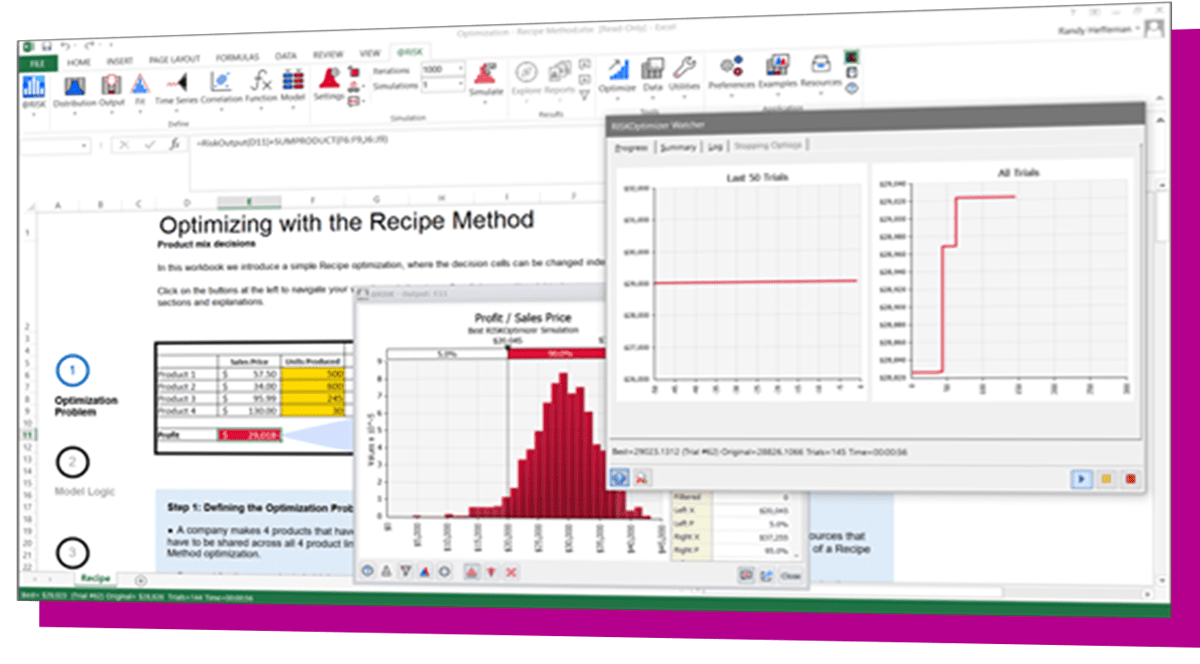
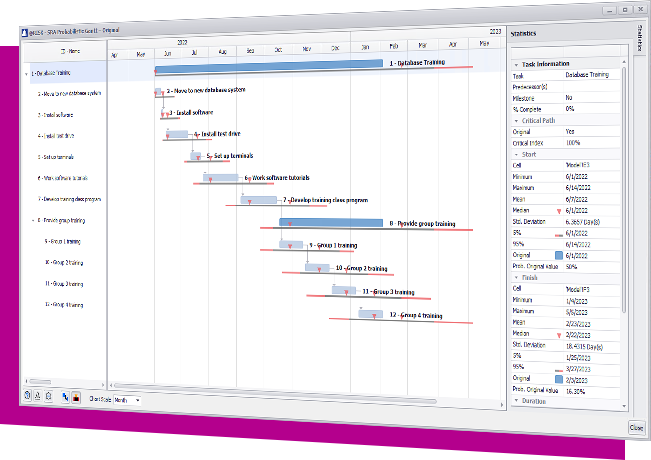
The DecisionTools Suite is an integrated set of programs for risk analysis and decision making under uncertainty. Each component of the DecisionTools Suite integrates seamlessly with Microsoft Excel and performs powerful analyses, but together they let you achieve more complete results that can help you make decisions with confidence. Learn more about each below and see which tools are available in each edition.
Learn more
Learn more
Learn more
Learn more
Learn more
Learn more
Learn more
Learn more
Learn how DecisionTools Suite has helped decision makers to improve risk and decision analysis efforts.